

Jeden zo základných kameňov technológie identifikácie a bezpečnosti - Dynamické riadenie prístupu (dynamická kontrola prístupu) v systéme Windows Server 2012 je funkčný Infraštruktúra klasifikácie súborov (Infraštruktúra klasifikácie súborov FCI). FCI sa používa na súborových serveroch organizácie a poskytuje možnosť vytvárať nové vlastnosti a atribúty(Vlastnosti klasifikácie súborov) pre klasifikácia súborov. FCI vám umožňuje automaticky klasifikovať súbory podľa obsahu súboru alebo adresára, v ktorom sú umiestnené; spravovať súbory (napríklad obdobie, počas ktorého je možný prístup k súboru); generovať správy ukazujúce distribúciu klasifikačných vlastností na súborovom serveri. Súbory založené na kľúčových slovách alebo vzoroch možno automaticky klasifikovať napríklad ako dôverné alebo obsahujúce osobné údaje. Avšak užívateľ (vlastník) bez použitia FCI môže súbory klasifikovať aj manuálne.
FCI je prvok riadenia dynamického prístupu, ktorý klasifikuje súbory priradením značiek, od ktorých závisí použitie politík DAC..
Prvá technológia Infraštruktúra klasifikácie súborov Predstavený v systéme Windows Server 2008 R2. Aké príležitosti poskytla? Pomocou FCI je možné implementovať rôzne scenáre spracovania dokumentov v úložiskách súborov (vrátane scén obsahujúcich dôverné informácie): zhromažďovanie, šifrovanie, prenos, archivácia, odosielanie po trase a mazanie súborov. Pomocou FCI môžete napríklad implementovať skript, ktorý vám umožní automaticky prenášať súbory z drahého úložiska na lacnejšie a pomalšie na základe klasifikácie súborov, alebo napríklad automaticky sprístupniť súbory po určitom čase neprístupnými..
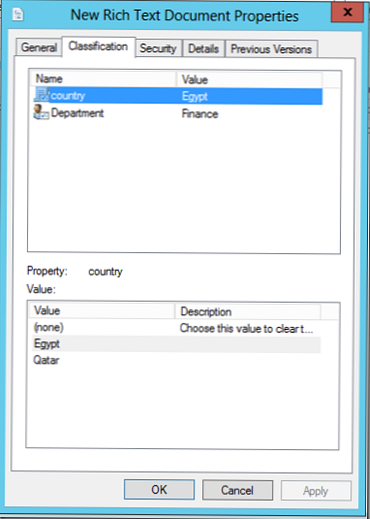
Na obrázku nižšie je uvedený príklad súboru, ktorý je klasifikovaný ako patriaci k egyptskej krajine a ministerstvu financií. Atribúty klasifikácie môžu byť absolútne čokoľvek: napríklad priorita, súkromie, umiestnenie, organizácia atď..
Ako ručne klasifikovať súbor alebo adresár
Súbory a adresáre je možné klasifikovať manuálne otvorením okna vlastností objektu a výberom možnosti „klasifikáciaV našom príklade z rozbaľovacieho zoznamu preddefinovaných hodnôt môžete vybrať ďalšie hodnoty pre atribúty krajiny a oddelenia..
Automatická klasifikácia
Ak chcete nakonfigurovať automatickú klasifikáciu objektov v systéme Windows Server 2012, na inštaláciu roly musíte použiť konzolu Server Manager Súborový server (súborový server).
Inštaláciou komponentu Správca zdrojov súborového servera (FSRM), otvorte príslušnú konzolu MMC a medzi známymi skupinami Kvóta, Skríning súborov a Správa súborov uvidíte novú podsekciu Riadenie klasifikácie (riadenie klasifikácie), ktoré pozostáva z dvoch oddielov:
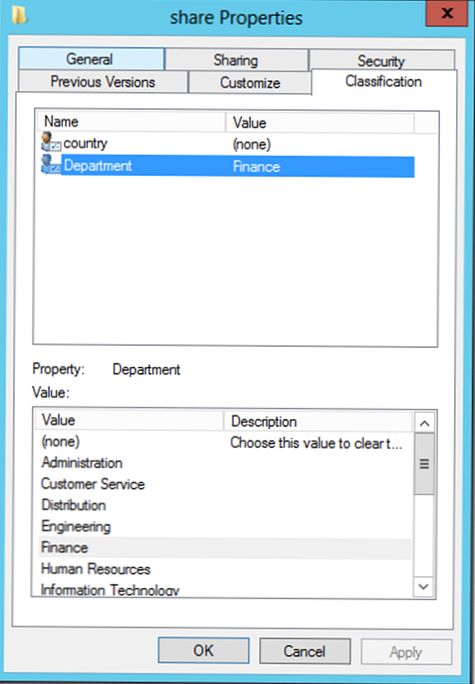
- Vlastnosti klasifikácie - slúži na vytvorenie atribútov klasifikácie (v našom príklade ide o atribúty krajiny a oddelenia, ktoré majú globálny stav, pretože sa uverejňujú v AD)
- Klasifikačné pravidlá - pravidlá automatickej klasifikácie

Ak chcete nastaviť automatickú klasifikáciu dokumentov, musíte si vytvoriť klasifikačné pravidlo.
Jedným zo spôsobov, ako usporiadať automatickú klasifikáciu súborov na základe umiestnenia, je vlastnosť klasifikácie - zložkapoužívanie. Toto je preddefinovaná vlastnosť uložená v sekcii Vlastnosti klasifikácie. Štandardne definuje 4 typy údajov:
- Dáta aplikácie - Dáta aplikácie
- Zálohy - zálohovacie údaje
- Údaje o skupine - údaje o skupine
- Súbory používateľov - Súbory používateľov
Tu si môžete vytvoriť svoje vlastné typy údajov..
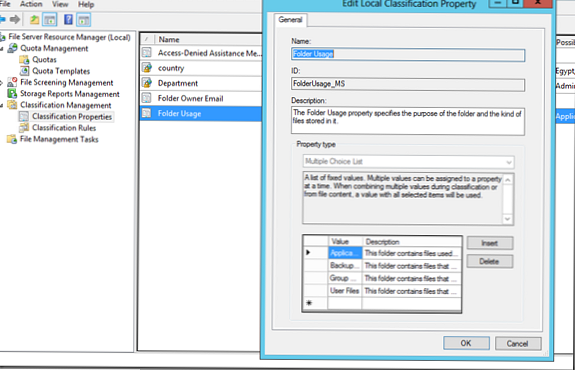
Tu si vytvoríme vlastné typy priečinkov pre finančné (finančné) a inžinierske oddelenie (technické) a potom musíme určiť, ktoré súbory patria k tomu oddeleniu (dátový typ). Ak to chcete urobiť, kliknite na prázdne miesto v konzole FSRM pod položkou klasifikáciavlastnosti a vyberte sadazložkamanagementvlastnosti
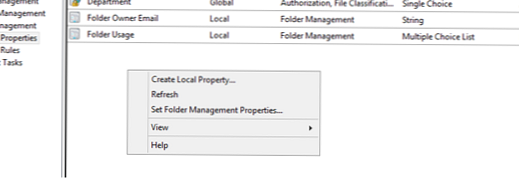
Vyberte nehnuteľnosť zložkapoužívanie a určte priečinky, ktoré bude používať každé oddelenie alebo ktoré obsahujú konkrétny typ údajov. Malo by však byť zrejmé, že v tomto prípade nie je nakonfigurovaná klasifikácia súborov (nakonfigurujeme ju neskôr), určíme vlastníctvo priečinkov, ktoré použijeme v klasifikačnom pravidle.
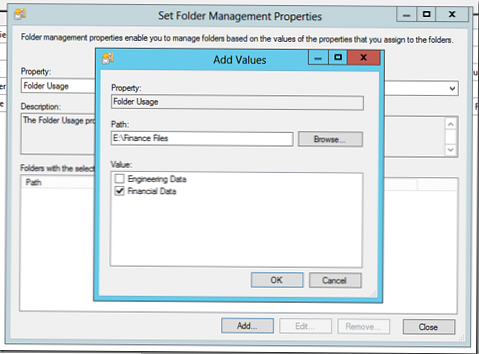
Nastavili sme to takto:
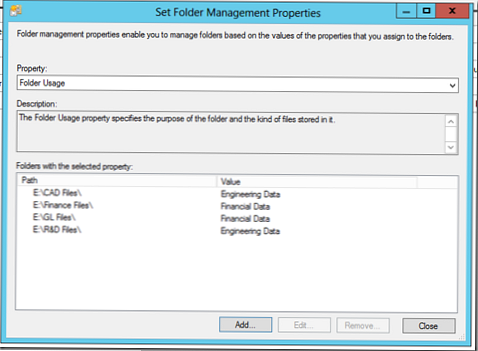
Vytvorte pravidlo klasifikácie údajov
Nadišiel čas v sekcii klasifikáciapravidlá vytvorte nové pravidlo (kontextová ponuka Create Rule Rule):
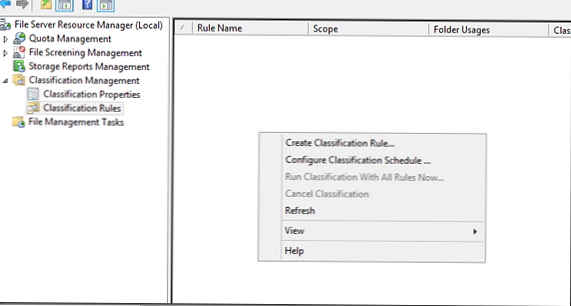
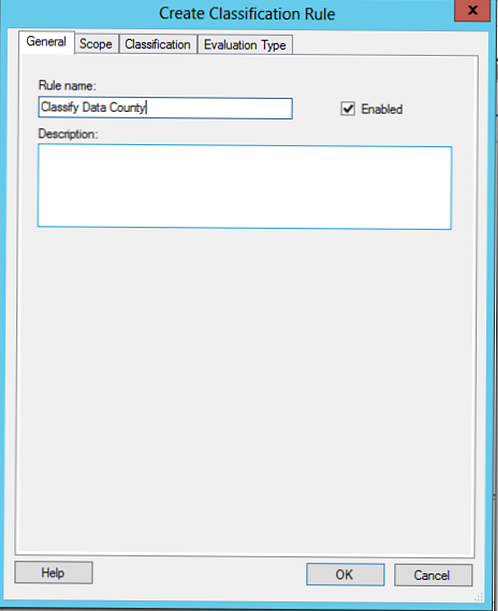
Uveďte názov pravidla (vytvárame pravidlo na klasifikáciu súborov ako patriacich finančnému oddeleniu).
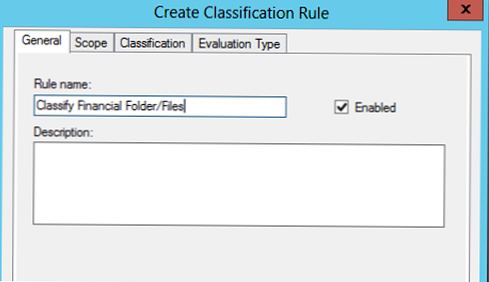
pútko rozsah označíme adresáre, ktoré je potrebné vziať do úvahy pri vykonávaní klasifikácie, vyberieme pravidlo vytvorené skôr finančnéúdaje (automaticky pridá všetky predtým vybrané priečinky), adresáre môžete pridať aj manuálne (v príklade je to E: \ share1).
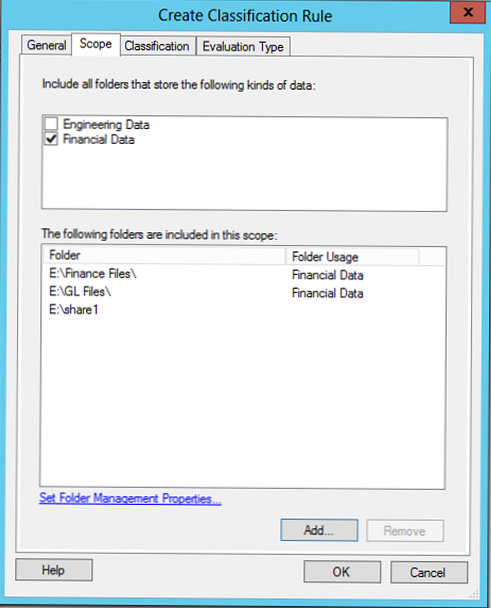
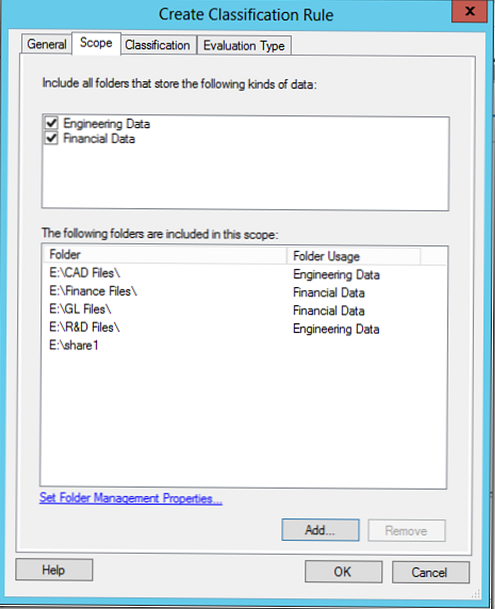
pútko klasifikácia Môžete si vybrať jednu z dvoch klasifikačných metód:
- Klasifikácia priečinkov - klasifikácia založená na adresári (atribúty sa vzťahujú na všetky súbory adresárov)
- Klasifikácia obsahu - klasifikácia podľa obsahu súboru. V takom prípade sa všetky súbory v adresári vyhľadávajú podľa kľúčových slov, vzorov alebo regulárnych výrazov (čísla projektov, kreditné karty, identifikátory oddelení atď.)..
Snímka obrazovky zobrazuje pravidlo klasifikácie na základe adresárov, pravidlo klasifikácie podľa obsahu bude uvedené nižšie.
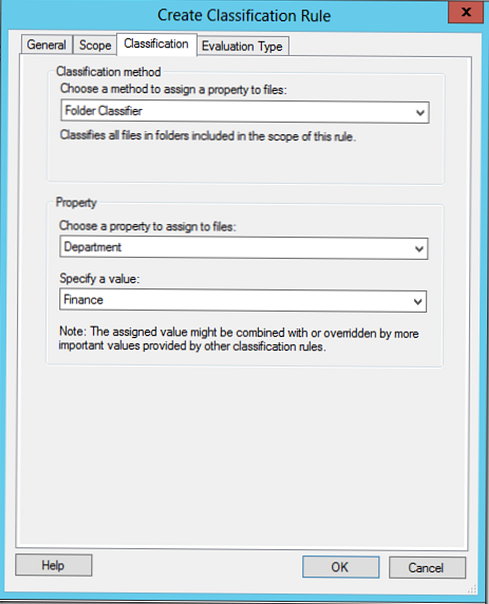
pútko Typ hodnotiacej hodnoty Je uvedený postup na uplatňovanie a opätovné uplatňovanie klasifikačných pravidiel na spisy. V nasledujúcom príklade sme uviedli, že systém môže prepísať aktuálnu klasifikáciu, čím zaručujeme, že klasifikácia používateľa bude prepísaná firemným pravidlom..

V nasledujúcom klasifikačnom pravidle vytvoríme klasifikačné pravidlo založené na obsahu súboru:
Toto pravidlo klasifikuje údaje podľa krajín, preto k nim pridáme katalógy technických a finančných oddelení.
V tomto klasifikačnom pravidle sa na základe obsahu súboru pokúsime klasifikovať údaje týkajúce sa Egyptskej krajiny.
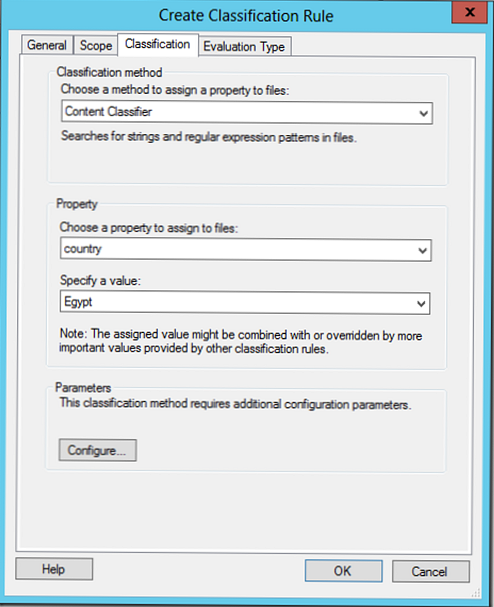
V časti Parametre vyberte položku Konfigurácia. V zobrazenom okne môžete vyhľadávať na základe regulárnych výrazov, reťazcov alebo reťazcov citlivých na veľkosť písmen..
Pomocou regulárnych výrazov môžete vyhľadávať v textových dokumentoch (vrátane súboru TIFF) podľa rôznych kritérií, napríklad:
- Prítomnosť koreňov v slove, nevenovanie pozornosti prípadom a príponám
- Prítomnosť slov alebo fráz v náhodnom poradí
- Dostupnosť údajov v špecifickom formáte, ako sú čísla kreditných kariet, telefónne čísla, pasové údaje alebo e-mailové adresy
- Splnenie podmienok pre určité množstvo stretnutí požadovaných údajov v súbore (napríklad najmenej 3 kreditné karty alebo telefónne čísla)
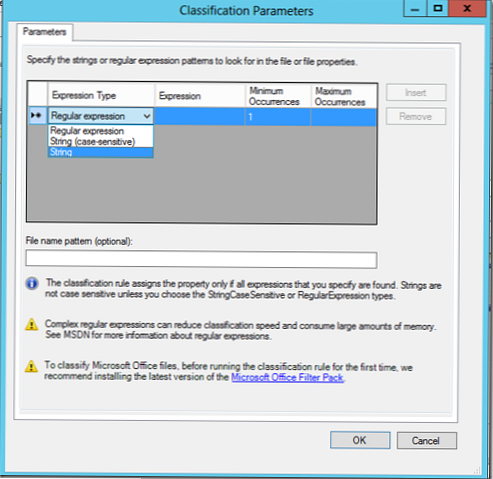
V našom príklade vyhľadáme dokumenty pomocou kľúčového slova Egypt, a ak sa nájde, súbor by sa mal klasifikovať podľa tohto pravidla (v dokumente môžete určiť minimálny a maximálny počet výskytov kľúčového slova)..
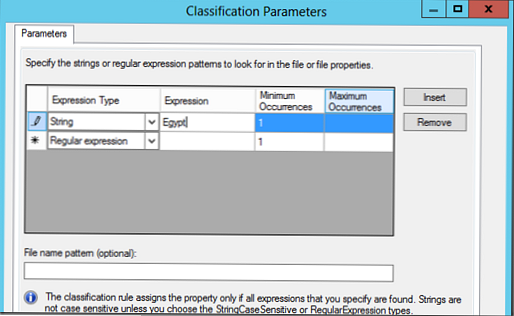
Vytvorili sme teda dve klasifikačné pravidlá:
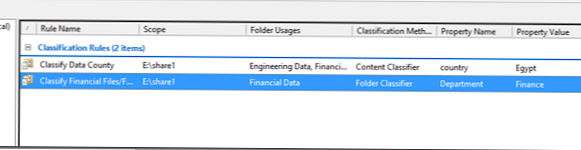
Teraz skúsme spustiť automatickú klasifikáciu súborov. Predpokladajme, že máme 2 súbory, z ktorých jeden obsahuje slovo Egypt a druhý neobsahuje. Tieto súbory sú umiestnené v adresároch „Finančné súbory“ a „Súbory výskumu a vývoja“, ako vidíte, v súčasnosti nie sú nijako klasifikované..
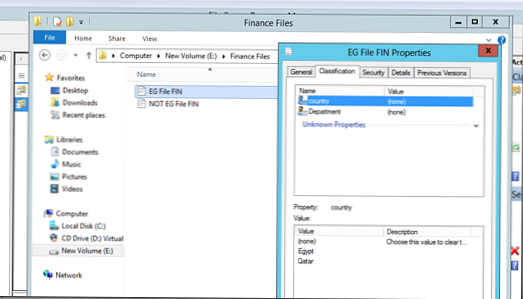
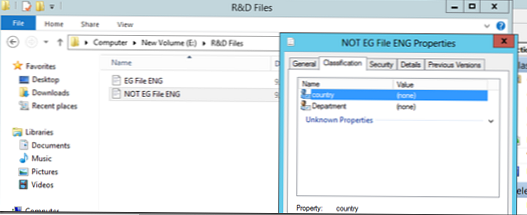
Spustite naše pravidlá klasifikácie (Spustite klasifikáciu so všetkými pravidlami):
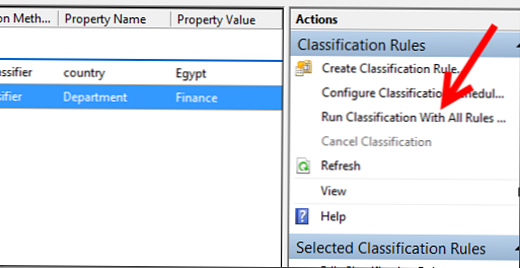
Výsledky pravidiel možno nájsť v správach v správach..

Ako vidíte, všetko fungovalo správne, súborom s kľúčovým slovom bola priradená správna krajina a celý obsah katalógu finančného oddelenia bol priradený k atribútu Finance..
V tejto fáze sa nevykonali žiadne operácie s utajovanými súbormi, jednoducho sa označili s potrebnými atribútmi. V budúcnosti môžete na základe klasifikácie súborov s nimi vykonávať rôzne operácie, najmä šifrovať súbory pomocou služby AD RMS (príklad použitia je opísaný v článku Šifrovanie súborov pomocou služby AD RMS založených na infraštruktúre klasifikácie súborov Windows Server 2012) alebo riadiť prístup k súborom prostredníctvom systému Windows Server 2012 Dynamic Access Control. Tieto aspekty zvážime v ďalších článkoch v sérii..

{kind=link}